资料
无所不知的Scrapy爬虫框架的介绍
在前面编写爬虫的时候,如果我们使用 requests、aiohttp 等库,需要从头至尾把爬虫完整地实现一遍,比如说异常处理、爬取调度等,如果写的多了,的确会比较麻烦。
那么有没有什么办法可以提升我们编写爬虫的效率呢?当然是有的,那就是利用现有的爬虫框架。
说到 Python 的爬虫框架,Scrapy 当之无愧是最流行最强大的框架了。本节我们就来初步认识一下 Scrapy,后面的课时我们会对 Scrapy 的功能模块进行详细介绍。
Scrapy 介绍
Scrapy 是一个基于 Twisted 的异步处理框架,是纯 Python 实现的爬虫框架,其架构清晰,模块之间的耦合程度低,可扩展性极强,可以灵活完成各种需求。我们只需要定制开发几个模块就可以轻松实现一个爬虫。
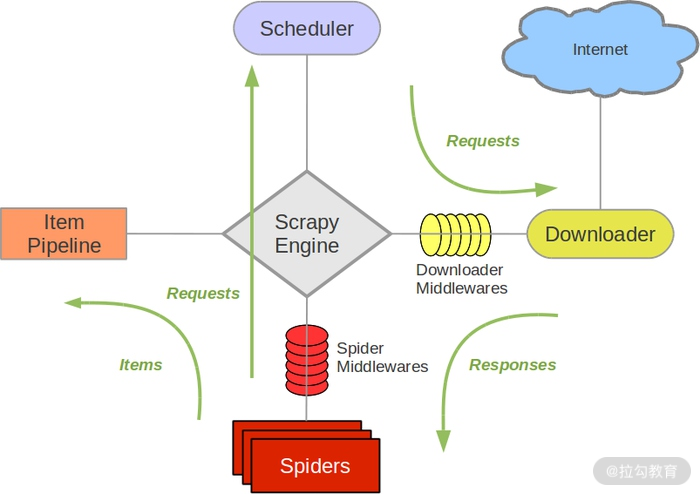
首先我们来看下 Scrapy 框架的架构,如图所示:
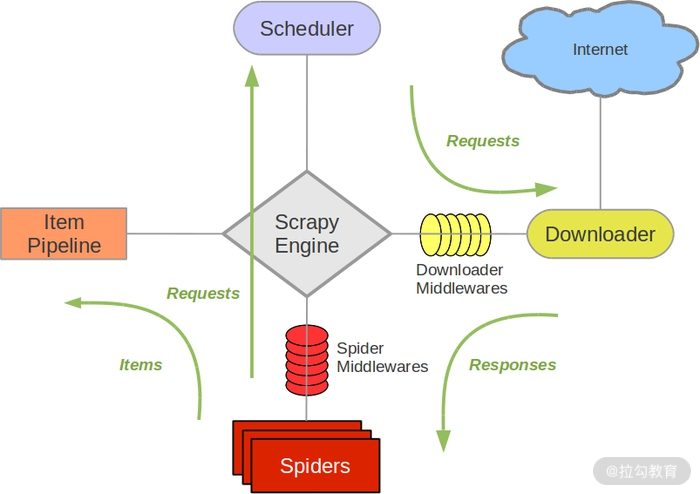
它可以分为如下的几个部分。
-
Engine(引擎):用来处理整个系统的数据流处理、触发事务,是整个框架的核心。
-
Item(项目):定义了爬取结果的数据结构,爬取的数据会被赋值成该对象。
-
Scheduler(调度器):用来接受引擎发过来的请求并加入队列中,并在引擎再次请求的时候提供给引擎。
-
Downloader(下载器):用于下载网页内容,并将网页内容返回给蜘蛛。
-
Spiders(蜘蛛):其内定义了爬取的逻辑和网页的解析规则,它主要负责解析响应并生成提取结果和新的请求。
-
Item Pipeline(项目管道):负责处理由蜘蛛从网页中抽取的项目,它的主要任务是清洗、验证和存储数据。
-
Downloader Middlewares(下载器中间件):位于引擎和下载器之间的钩子框架,主要是处理引擎与下载器之间的请求及响应。
-
Spider Middlewares(蜘蛛中间件):位于引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛输入的响应和输出的结果及新的请求。
初看起来的确比较懵,不过不用担心,我们在后文会结合案例来对 Scrapy 的功能模块进行介绍,相信你会慢慢地理解各个模块的含义及功能。
数据流
了解了架构,下一步就是要了解它是怎样进行数据爬取和处理的,所以我们接下来需要了解 Scrapy 的数据流机制。
Scrapy 中的数据流由引擎控制,其过程如下:
-
Engine 首先打开一个网站,找到处理该网站的 Spider 并向该 Spider 请求第一个要爬取的 URL。
-
Engine 从 Spider 中获取到第一个要爬取的 URL 并通过 Scheduler 以 Request 的形式调度。
-
Engine 向 Scheduler 请求下一个要爬取的 URL。
-
Scheduler 返回下一个要爬取的 URL 给 Engine,Engine 将 URL 通过 Downloader Middlewares 转发给 Downloader 下载。
-
一旦页面下载完毕, Downloader 生成一个该页面的 Response,并将其通过 Downloader Middlewares 发送给 Engine。
-
Engine 从下载器中接收到 Response 并通过 Spider Middlewares 发送给 Spider 处理。
-
Spider 处理 Response 并返回爬取到的 Item 及新的 Request 给 Engine。
-
Engine 将 Spider 返回的 Item 给 Item Pipeline,将新的 Request 给 Scheduler。
-
重复第二步到最后一步,直到 Scheduler 中没有更多的 Request,Engine 关闭该网站,爬取结束。
通过多个组件的相互协作、不同组件完成工作的不同、组件对异步处理的支持,Scrapy 最大限度地利用了网络带宽,大大提高了数据爬取和处理的效率。
安装
了解了 Scrapy 的基本情况之后,下一步让我们来动手安装一下吧。
Scrapy 的安装方法当然首推官方文档,其地址为:https://docs.scrapy.org/en/latest/intro/install.html,另外也可以参考 https://cuiqingcai.com/5421.html。
安装完成之后,如果可以正常使用 scrapy 命令,那就是可以了。
项目结构
既然 Scrapy 是框架,那么 Scrapy 一定帮我们预先配置好了很多可用的组件和编写爬虫时所用的脚手架,也就是预生成一个项目框架,我们可以基于这个框架来快速编写爬虫。
Scrapy 框架是通过命令行来创建项目的,创建项目的命令如下:
scrapy startproject demo
执行完成之后,在当前运行目录下便会出现一个文件夹,叫作 demo,这就是一个 Scrapy 项目框架,我们可以基于这个项目框架来编写爬虫。
项目文件结构如下所示:
scrapy.cfg
project/
__init__.py
items.py
pipelines.py
settings.py
middlewares.py
spiders/
__init__.py
spider1.py
spider2.py
...
在此要将各个文件的功能描述如下:
-
scrapy.cfg:它是 Scrapy 项目的配置文件,其内定义了项目的配置文件路径、部署相关信息等内容。
-
items.py:它定义 Item 数据结构,所有的 Item 的定义都可以放这里。
-
pipelines.py:它定义 Item Pipeline 的实现,所有的 Item Pipeline 的实现都可以放这里。
-
settings.py:它定义项目的全局配置。
-
middlewares.py:它定义 Spider Middlewares 和 Downloader Middlewares 的实现。
-
spiders:其内包含一个个 Spider 的实现,每个 Spider 都有一个文件。
好了,到现在为止我们就大体知道了 Scrapy 的基本架构并实操创建了一个 Scrapy 项目,后面我们会详细了解 Scrapy 的用法,感受它的强大,下节课见。
初窥门路Scrapy的基本使用
接下来介绍一个简单的项目,完成一遍 Scrapy 抓取流程。通过这个过程,我们可以对 Scrapy 的基本用法和原理有大体了解。
本节目标
本节要完成的任务如下。
-
创建一个 Scrapy 项目。
-
创建一个 Spider 来抓取站点和处理数据。
-
通过命令行将抓取的内容导出。
-
将抓取的内容保存到 MongoDB 数据库。
本节抓取的目标站点为 http://quotes.toscrape.com/。
准备工作
我们需要安装好 Scrapy 框架、MongoDB 和 PyMongo 库。如果尚未安装,请参照之前几节的安装说明。
创建项目
创建一个 Scrapy 项目,项目文件可以直接用 scrapy 命令生成,命令如下所示:
scrapy startproject tutorial
这个命令可以在任意文件夹运行。如果提示权限问题,可以加 sudo 运行该命令。这个命令将会创建一个名为 tutorial 的文件夹,文件夹结构如下所示:
scrapy.cfg # Scrapy 部署时的配置文件
tutorial # 项目的模块,引入的时候需要从这里引入
__init__.py
items.py # Items 的定义,定义爬取的数据结构
middlewares.py # Middlewares 的定义,定义爬取时的中间件
pipelines.py # Pipelines 的定义,定义数据管道
settings.py # 配置文件
spiders # 放置 Spiders 的文件夹
__init__.py
创建 Spider
Spider 是自己定义的类,Scrapy 用它从网页里抓取内容,并解析抓取的结果。不过这个类必须继承 Scrapy 提供的 Spider 类 scrapy.Spider,还要定义 Spider 的名称和起始请求,以及怎样处理爬取后的结果的方法。
你也可以使用命令行创建一个 Spider。比如要生成 Quotes 这个 Spider,可以执行如下命令:
cd tutorial
scrapy genspider quotes
进入刚才创建的 tutorial 文件夹,然后执行 genspider 命令。第一个参数是 Spider 的名称,第二个参数是网站域名。执行完毕之后,spiders 文件夹中多了一个 quotes.py,它就是刚刚创建的 Spider,内容如下所示:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
pass
这里有三个属性——name、allowed_domains 和 start_urls,还有一个方法 parse。
-
name:它是每个项目唯一的名字,用来区分不同的 Spider。
-
allowed_domains:它是允许爬取的域名,如果初始或后续的请求链接不是这个域名下的,则请求链接会被过滤掉。
-
start_urls:它包含了 Spider 在启动时爬取的 url 列表,初始请求是由它来定义的。
-
parse:它是 Spider 的一个方法。默认情况下,被调用时 start_urls 里面的链接构成的请求完成下载执行后,返回的响应就会作为唯一的参数传递给这个函数。该方法负责解析返回的响应、提取数据或者进一步生成要处理的请求。
创建 Item
Item 是保存爬取数据的容器,它的使用方法和字典类似。不过,相比字典,Item 多了额外的保护机制,可以避免拼写错误或者定义字段错误。
创建 Item 需要继承 scrapy.Item 类,并且定义类型为 scrapy.Field 的字段。观察目标网站,我们可以获取到的内容有 text、author、tags。
定义 Item,此时将 items.py 修改如下:
import scrapy
class QuoteItem(scrapy.Item):
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
这里定义了三个字段,将类的名称修改为 QuoteItem,接下来爬取时我们会使用到这个 Item。
解析 Response
前面我们看到,parse 方法的参数 response 是 start_urls 里面的链接爬取后的结果。所以在 parse 方法中,我们可以直接对 response 变量包含的内容进行解析,比如浏览请求结果的网页源代码,或者进一步分析源代码内容,或者找出结果中的链接而得到下一个请求。
我们可以看到网页中既有我们想要的结果,又有下一页的链接,这两部分内容我们都要进行处理。
首先看看网页结构,如图所示。每一页都有多个 class 为 quote 的区块,每个区块内都包含 text、author、tags。那么我们先找出所有的 quote,然后提取每一个 quote 中的内容。
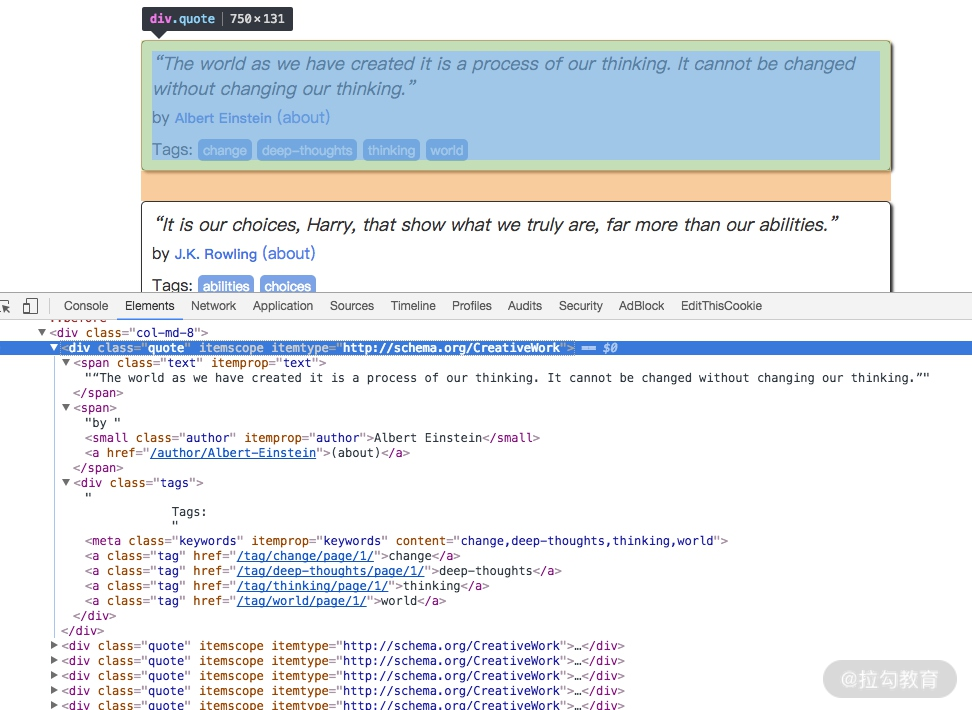
提取的方式可以是 CSS 选择器或 XPath 选择器。在这里我们使用 CSS 选择器进行选择,parse 方法的改写如下所示:
def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
text = quote.css('.text::text').extract_first()
author = quote.css('.author::text').extract_first()
tags = quote.css('.tags .tag::text').extract()
这里首先利用选择器选取所有的 quote,并将其赋值为 quotes 变量,然后利用 for 循环对每个 quote 遍历,解析每个 quote 的内容。
对 text 来说,观察到它的 class 为 text,所以可以用 .text 选择器来选取,这个结果实际上是整个带有标签的节点,要获取它的正文内容,可以加 ::text 来获取。这时的结果是长度为 1 的列表,所以还需要用 extract_first 方法来获取第一个元素。而对于 tags 来说,由于我们要获取所有的标签,所以用 extract 方法获取整个列表即可。
以第一个 quote 的结果为例,各个选择方法及结果的说明如下内容。
源码如下:
<div class="quote" itemscope=""itemtype="http://schema.org/CreativeWork">
<span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>
<span>by <small class="author" itemprop="author">Albert Einstein</small>
<a href="/author/Albert-Einstein">(about)</a>
</span>
<div class="tags">
Tags:
<meta class="keywords" itemprop="keywords" content="change,deep-thoughts,thinking,world">
<a class="tag" href="/tag/change/page/1/">change</a>
<a class="tag" href="/tag/deep-thoughts/page/1/">deep-thoughts</a>
<a class="tag" href="/tag/thinking/page/1/">thinking</a>
<a class="tag" href="/tag/world/page/1/">world</a>
</div>
</div>
不同选择器的返回结果如下。
quote.css('.text')
[<Selector xpath="descendant-or-self::*[@class and contains(concat(' ', normalize-space(@class), ' '), ' text ')]"data='<span class="text"itemprop="text">“The '>]
quote.css('.text::text')
[<Selector xpath="descendant-or-self::*[@class and contains(concat(' ', normalize-space(@class), ' '), ' text ')]/text()"data='“The world as we have created it is a pr'>]
quote.css('.text').extract()
['<span class="text"itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>']
quote.css('.text::text').extract()
['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”']
quote.css('.text::text').extract_first()
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”
所以,对于 text,获取结果的第一个元素即可,所以使用 extract_first 方法,对于 tags,要获取所有结果组成的列表,所以使用 extract 方法。
使用 Item
上文定义了 Item,接下来就要使用它了。Item 可以理解为一个字典,不过在声明的时候需要实例化。然后依次用刚才解析的结果赋值 Item 的每一个字段,最后将 Item 返回即可。
QuotesSpider 的改写如下所示:
import scrapy
from tutorial.items import QuoteItem
class QuotesSpider(scrapy.Spider):
name = "quotes"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
item = QuoteItem()
item['text'] = quote.css('.text::text').extract_first()
item['author'] = quote.css('.author::text').extract_first()
item['tags'] = quote.css('.tags .tag::text').extract()
yield item
如此一来,首页的所有内容被解析出来,并被赋值成了一个个 QuoteItem。
后续 Request
上面的操作实现了从初始页面抓取内容。那么,下一页的内容该如何抓取?这就需要我们从当前页面中找到信息来生成下一个请求,然后在下一个请求的页面里找到信息再构造下一个请求。这样循环往复迭代,从而实现整站的爬取。
将刚才的页面拉到最底部,如图所示。
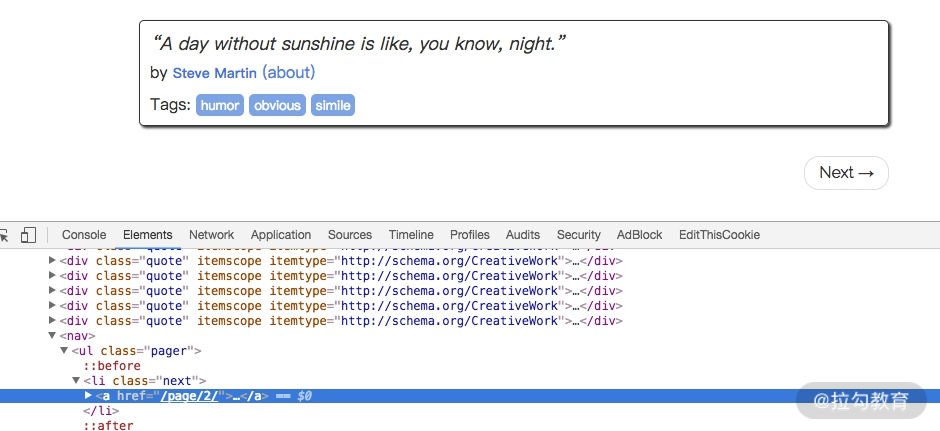
有一个 Next 按钮,查看一下源代码,可以发现它的链接是 /page/2/,实际上全链接就是:http://quotes.toscrape.com/page/2,通过这个链接我们就可以构造下一个请求。
构造请求时需要用到 scrapy.Request。这里我们传递两个参数——url 和 callback,这两个参数的说明如下。
-
url:它是请求链接。
-
callback:它是回调函数。当指定了该回调函数的请求完成之后,获取到响应,引擎会将该响应作为参数传递给这个回调函数。回调函数进行解析或生成下一个请求,回调函数如上文的 parse() 所示。
由于 parse 就是解析 text、author、tags 的方法,而下一页的结构和刚才已经解析的页面结构是一样的,所以我们可以再次使用 parse 方法来做页面解析。
接下来我们要做的就是利用选择器得到下一页链接并生成请求,在 parse 方法后追加如下的代码:
next = response.css('.pager .next a::attr(href)').extract_first()
url = response.urljoin(next)
yield scrapy.Request(url=url, callback=self.parse)
第一句代码首先通过 CSS 选择器获取下一个页面的链接,即要获取 a 超链接中的 href 属性。这里用到了 ::attr(href) 操作。然后再调用 extract_first 方法获取内容。
第二句代码调用了 urljoin 方法,urljoin() 方法可以将相对 URL 构造成一个绝对的 URL。例如,获取到的下一页地址是 /page/2,urljoin 方法处理后得到的结果就是:http://quotes.toscrape.com/page/2/。
第三句代码通过 url 和 callback 变量构造了一个新的请求,回调函数 callback 依然使用 parse 方法。这个请求完成后,响应会重新经过 parse 方法处理,得到第二页的解析结果,然后生成第二页的下一页,也就是第三页的请求。这样爬虫就进入了一个循环,直到最后一页。
通过几行代码,我们就轻松实现了一个抓取循环,将每个页面的结果抓取下来了。现在,改写之后的整个 Spider 类如下所示:
import scrapy
from tutorial.items import QuoteItem
class QuotesSpider(scrapy.Spider):
name = "quotes"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
item = QuoteItem()
item['text'] = quote.css('.text::text').extract_first()
item['author'] = quote.css('.author::text').extract_first()
item['tags'] = quote.css('.tags .tag::text').extract()
yield item
next = response.css('.pager .next a::attr("href")').extract_first()
url = response.urljoin(next)
yield scrapy.Request(url=url, callback=self.parse)
运行
接下来,进入目录,运行如下命令:
scrapy crawl quotes
就可以看到 Scrapy 的运行结果了。
2020-02-19 13:37:20 [scrapy.utils.log] INFO: Scrapy 1.3.0 started (bot: tutorial)
2020-02-19 13:37:20 [scrapy.utils.log] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'tutorial.spiders', 'SPIDER_MODULES': ['tutorial.spiders'], 'ROBOTSTXT_OBEY': True, 'BOT_NAME': 'tutorial'}
2020-02-19 13:37:20 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.logstats.LogStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.corestats.CoreStats']
2020-02-19 13:37:20 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2020-02-19 13:37:20 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2020-02-19 13:37:20 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2020-02-19 13:37:20 [scrapy.core.engine] INFO: Spider opened
2020-02-19 13:37:20 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2020-02-19 13:37:20 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2020-02-19 13:37:21 [scrapy.core.engine] DEBUG: Crawled (404) <GET http://quotes.toscrape.com/robots.txt> (referer: None)
2020-02-19 13:37:21 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com/> (referer: None)
2020-02-19 13:37:21 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/>
{'author': u'Albert Einstein',
'tags': [u'change', u'deep-thoughts', u'thinking', u'world'],
'text': u'\u201cThe world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.\u201d'}
2020-02-19 13:37:21 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/>
{'author': u'J.K. Rowling',
'tags': [u'abilities', u'choices'],
'text': u'\u201cIt is our choices, Harry, that show what we truly are, far more than our abilities.\u201d'}
...
2020-02-19 13:37:27 [scrapy.core.engine] INFO: Closing spider (finished)
2020-02-19 13:37:27 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 2859,
'downloader/request_count': 11,
'downloader/request_method_count/GET': 11,
'downloader/response_bytes': 24871,
'downloader/response_count': 11,
'downloader/response_status_count/200': 10,
'downloader/response_status_count/404': 1,
'dupefilter/filtered': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2017, 2, 19, 5, 37, 27, 227438),
'item_scraped_count': 100,
'log_count/DEBUG': 113,
'log_count/INFO': 7,
'request_depth_max': 10,
'response_received_count': 11,
'scheduler/dequeued': 10,
'scheduler/dequeued/memory': 10,
'scheduler/enqueued': 10,
'scheduler/enqueued/memory': 10,
'start_time': datetime.datetime(2017, 2, 19, 5, 37, 20, 321557)}
2020-02-19 13:37:27 [scrapy.core.engine] INFO: Spider closed (finished)
这里只是部分运行结果,中间一些抓取结果已省略。
首先,Scrapy 输出了当前的版本号,以及正在启动的项目名称。接着输出了当前 settings.py 中一些重写后的配置。然后输出了当前所应用的 Middlewares 和 Pipelines。Middlewares 默认是启用的,可以在 settings.py 中修改。Pipelines 默认是空,同样也可以在 settings.py 中配置。后面会对它们进行讲解。
接下来就是输出各个页面的抓取结果了,可以看到爬虫一边解析,一边翻页,直至将所有内容抓取完毕,然后终止。
最后,Scrapy 输出了整个抓取过程的统计信息,如请求的字节数、请求次数、响应次数、完成原因等。
整个 Scrapy 程序成功运行。我们通过非常简单的代码就完成了一个网站内容的爬取,这样相比之前一点点写程序简洁很多。
保存到文件
运行完 Scrapy 后,我们只在控制台看到了输出结果。如果想保存结果该怎么办呢?
要完成这个任务其实不需要任何额外的代码,Scrapy 提供的 Feed Exports 可以轻松将抓取结果输出。例如,我们想将上面的结果保存成 JSON 文件,可以执行如下命令:
scrapy crawl quotes -o quotes.json
命令运行后,项目内多了一个 quotes.json 文件,文件包含了刚才抓取的所有内容,内容是 JSON 格式。
另外我们还可以每一个 Item 输出一行 JSON,输出后缀为 jl,为 jsonline 的缩写,命令如下所示:
scrapy crawl quotes -o quotes.jl
或
scrapy crawl quotes -o quotes.jsonlines
输出格式还支持很多种,例如 csv、xml、pickle、marshal 等,还支持 ftp、s3 等远程输出,另外还可以通过自定义 ItemExporter 来实现其他的输出。
例如,下面命令对应的输出分别为 csv、xml、pickle、marshal 格式以及 ftp 远程输出:
scrapy crawl quotes -o quotes.csv
scrapy crawl quotes -o quotes.xml
scrapy crawl quotes -o quotes.pickle
scrapy crawl quotes -o quotes.marshal
scrapy crawl quotes -o ftp://user:[email protected]/path/to/quotes.csv
其中,ftp 输出需要正确配置用户名、密码、地址、输出路径,否则会报错。
通过 Scrapy 提供的 Feed Exports,我们可以轻松地输出抓取结果到文件。对于一些小型项目来说,这应该足够了。不过如果想要更复杂的输出,如输出到数据库等,我们可以使用 Item Pileline 来完成。
使用 Item Pipeline
如果想进行更复杂的操作,如将结果保存到 MongoDB 数据库,或者筛选某些有用的 Item,则我们可以定义 Item Pipeline 来实现。
Item Pipeline 为项目管道。当 Item 生成后,它会自动被送到 Item Pipeline 进行处理,我们常用 Item Pipeline 来做如下操作。
-
清洗 HTML 数据;
-
验证爬取数据,检查爬取字段;
-
查重并丢弃重复内容;
-
将爬取结果储存到数据库。
要实现 Item Pipeline 很简单,只需要定义一个类并实现 process_item 方法即可。启用 Item Pipeline 后,Item Pipeline 会自动调用这个方法。process_item 方法必须返回包含数据的字典或 Item 对象,或者抛出 DropItem 异常。
process_item 方法有两个参数。一个参数是 item,每次 Spider 生成的 Item 都会作为参数传递过来。另一个参数是 spider,就是 Spider 的实例。
接下来,我们实现一个 Item Pipeline,筛掉 text 长度大于 50 的 Item,并将结果保存到 MongoDB。
修改项目里的 pipelines.py 文件,之前用命令行自动生成的文件内容可以删掉,增加一个 TextPipeline 类,内容如下所示:
from scrapy.exceptions import DropItem
class TextPipeline(object):
def __init__(self):
self.limit = 50
def process_item(self, item, spider):
if item['text']:
if len(item['text']) > self.limit:
item['text'] = item['text'][0:self.limit].rstrip() + '...'
return item
else:
return DropItem('Missing Text')
这段代码在构造方法里定义了限制长度为 50,实现了 process_item 方法,其参数是 item 和 spider。首先该方法判断 item 的 text 属性是否存在,如果不存在,则抛出 DropItem 异常;如果存在,再判断长度是否大于 50,如果大于,那就截断然后拼接省略号,再将 item 返回即可。
接下来,我们将处理后的 item 存入 MongoDB,定义另外一个 Pipeline。同样在 pipelines.py 中,我们实现另一个类 MongoPipeline,内容如下所示:
import pymongo
class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def process_item(self, item, spider):
name = item.__class__.__name__
self.db[name].insert(dict(item))
return item
def close_spider(self, spider):
self.client.close()
MongoPipeline 类实现了 API 定义的另外几个方法。
-
from_crawler:这是一个类方法,用 @classmethod 标识,是一种依赖注入的方式,方法的参数就是 crawler,通过 crawler 这个参数我们可以拿到全局配置的每个配置信息,在全局配置 settings.py 中我们可以定义 MONGO_URI 和 MONGO_DB 来指定 MongoDB 连接需要的地址和数据库名称,拿到配置信息之后返回类对象即可。所以这个方法的定义主要是用来获取 settings.py 中的配置的。
-
open_spider:当 Spider 被开启时,这个方法被调用。在这里主要进行了一些初始化操作。
-
close_spider:当 Spider 被关闭时,这个方法会调用,在这里将数据库连接关闭。
最主要的 process_item 方法则执行了数据插入操作。
定义好 TextPipeline 和 MongoPipeline 这两个类后,我们需要在 settings.py 中使用它们。MongoDB 的连接信息还需要定义。
我们在 settings.py 中加入如下内容:
ITEM_PIPELINES = {
'tutorial.pipelines.TextPipeline': 300,
'tutorial.pipelines.MongoPipeline': 400,
}
MONGO_URI='localhost'
MONGO_DB='tutorial'
赋值 ITEM_PIPELINES 字典,键名是 Pipeline 的类名称,键值是调用优先级,是一个数字,数字越小则对应的 Pipeline 越先被调用。
再重新执行爬取,命令如下所示:
scrapy crawl quotes
爬取结束后,MongoDB 中创建了一个 tutorial 的数据库、QuoteItem 的表,如图所示。
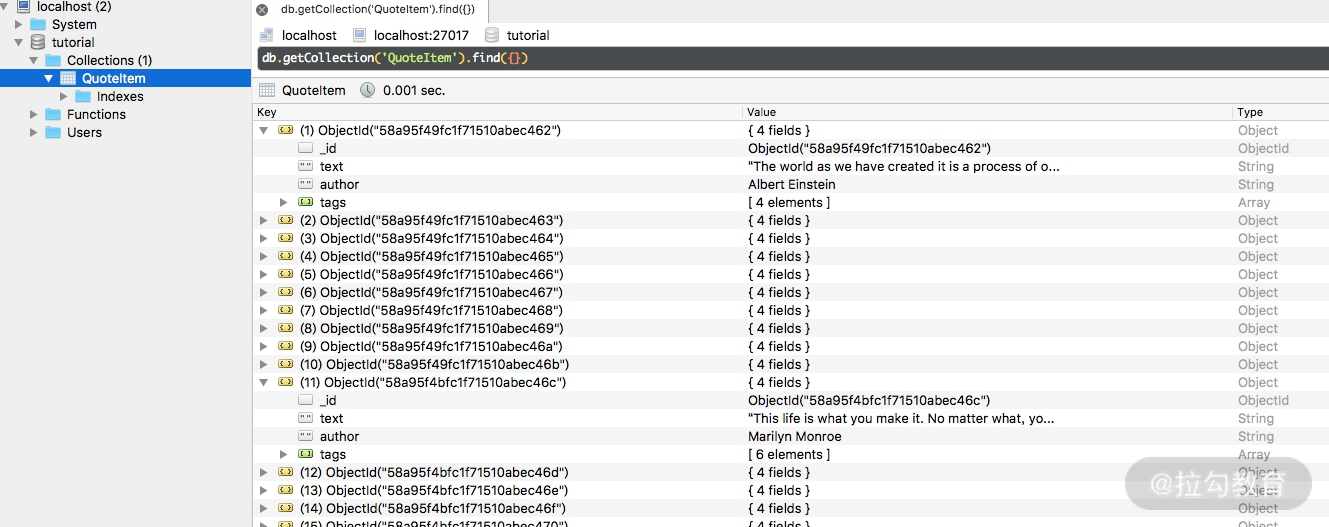
长的 text 已经被处理并追加了省略号,短的 text 保持不变,author 和 tags 也都相应保存。
代码
本节代码地址:https://github.com/Python3WebSpider/ScrapyTutorial。
结语
我们通过抓取 Quotes 网站完成了整个 Scrapy 的简单入门。但这只是冰山一角,还有很多内容等待我们去探索。
灵活好用的Spider的用法
在上一节课我们通过实例了解了 Scrapy 的基本使用方法,在这个过程中,我们用到了 Spider 来编写爬虫逻辑,同时用到了一些选择器来对结果进行选择。
在这一节课,我们就对 Spider 和 Selector 的基本用法作一个总结。
Spider 的用法
在 Scrapy 中,要抓取网站的链接配置、抓取逻辑、解析逻辑等其实都是在 Spider 中配置的。在前一节课的实例中,我们发现抓取逻辑也是在 Spider 中完成的。本节课我们就来专门了解一下 Spider 的基本用法。
Spider 运行流程
在实现 Scrapy 爬虫项目时,最核心的类便是 Spider 类了,它定义了如何爬取某个网站的流程和解析方式。简单来讲,Spider 要做的事就是如下两件:
-
定义爬取网站的动作;
-
分析爬取下来的网页。
对于 Spider 类来说,整个爬取循环如下所述。
-
以初始的 URL 初始化 Request,并设置回调函数。 当该 Request 成功请求并返回时,将生成 Response,并作为参数传给该回调函数。
-
在回调函数内分析返回的网页内容。返回结果可以有两种形式,一种是解析到的有效结果返回字典或 Item 对象。下一步可经过处理后(或直接)保存,另一种是解析到的下一个(如下一页)链接,可以利用此链接构造 Request 并设置新的回调函数,返回 Request。
-
如果返回的是字典或 Item 对象,可通过 Feed Exports 等形式存入文件,如果设置了 Pipeline 的话,可以经由 Pipeline 处理(如过滤、修正等)并保存。
-
如果返回的是 Reqeust,那么 Request 执行成功得到 Response 之后会再次传递给 Request 中定义的回调函数,可以再次使用选择器来分析新得到的网页内容,并根据分析的数据生成 Item。
通过以上几步循环往复进行,便完成了站点的爬取。
Spider 类分析
在上一节课的例子中我们定义的 Spider 继承自 scrapy.spiders.Spider,这个类是最简单最基本的 Spider 类,每个其他的 Spider 必须继承自这个类,还有后面要说明的一些特殊 Spider 类也都是继承自它。
这个类里提供了 start_requests 方法的默认实现,读取并请求 start_urls 属性,并根据返回的结果调用 parse 方法解析结果。另外它还有一些基础属性,下面对其进行讲解。
-
name:爬虫名称,是定义 Spider 名字的字符串。Spider 的名字定义了 Scrapy 如何定位并初始化 Spider,所以其必须是唯一的。 不过我们可以生成多个相同的 Spider 实例,这没有任何限制。 name 是 Spider 最重要的属性,而且是必需的。如果该 Spider 爬取单个网站,一个常见的做法是以该网站的域名名称来命名 Spider。例如,如果 Spider 爬取 mywebsite.com,该 Spider 通常会被命名为 mywebsite。
-
allowed_domains:允许爬取的域名,是可选配置,不在此范围的链接不会被跟进爬取。
-
start_urls:起始 URL 列表,当我们没有实现 start_requests 方法时,默认会从这个列表开始抓取。
-
custom_settings:这是一个字典,是专属于本 Spider 的配置,此设置会覆盖项目全局的设置,而且此设置必须在初始化前被更新,所以它必须定义成类变量。
-
crawler:此属性是由 from_crawler 方法设置的,代表的是本 Spider 类对应的 Crawler 对象,Crawler 对象中包含了很多项目组件,利用它我们可以获取项目的一些配置信息,如最常见的就是获取项目的设置信息,即 Settings。
-
settings:是一个 Settings 对象,利用它我们可以直接获取项目的全局设置变量。
除了一些基础属性,Spider 还有一些常用的方法,在此介绍如下。
-
start_requests:此方法用于生成初始请求,它必须返回一个可迭代对象,此方法会默认使用 start_urls 里面的 URL 来构造 Request,而且 Request 是 GET 请求方式。如果我们想在启动时以 POST 方式访问某个站点,可以直接重写这个方法,发送 POST 请求时我们使用 FormRequest 即可。
-
parse:当 Response 没有指定回调函数时,该方法会默认被调用,它负责处理 Response,处理返回结果,并从中提取出想要的数据和下一步的请求,然后返回。该方法需要返回一个包含 Request 或 Item 的可迭代对象。
-
closed:当 Spider 关闭时,该方法会被调用,在这里一般会定义释放资源的一些操作或其他收尾操作。
Selector 的用法
我们之前介绍了利用 Beautiful Soup、PyQuery,以及正则表达式来提取网页数据,这确实非常方便。而 Scrapy 还提供了自己的数据提取方法,即 Selector(选择器)。
Selector 是基于 lxml 构建的,支持 XPath 选择器、CSS 选择器,以及正则表达式,功能全面,解析速度和准确度非常高。
接下来我们将介绍 Selector 的用法。
直接使用
Selector 是一个可以独立使用的模块。我们可以直接利用 Selector 这个类来构建一个选择器对象,然后调用它的相关方法如 xpath、css 等来提取数据。
例如,针对一段 HTML 代码,我们可以用如下方式构建 Selector 对象来提取数据:
from scrapy import Selector
body = '<html><head><title>Hello World</title></head><body></body></html>'
selector = Selector(text=body)
title = selector.xpath('//title/text()').extract_first()
print(title)
运行结果:
Hello World
这里我们没有在 Scrapy 框架中运行,而是把 Scrapy 中的 Selector 单独拿出来使用了,构建的时候传入 text 参数,就生成了一个 Selector 选择器对象,然后就可以像前面我们所用的 Scrapy 中的解析方式一样,调用 xpath、css 等方法来提取了。
在这里我们查找的是源代码中的 title 中的文本,在 XPath 选择器最后加 text 方法就可以实现文本的提取了。
以上内容就是 Selector 的直接使用方式。同 Beautiful Soup 等库类似,Selector 其实也是强大的网页解析库。如果方便的话,我们也可以在其他项目中直接使用 Selector 来提取数据。
接下来,我们用实例来详细讲解 Selector 的用法。
Scrapy Shell
由于 Selector 主要是与 Scrapy 结合使用,如 Scrapy 的回调函数中的参数 response 直接调用 xpath() 或者 css() 方法来提取数据,所以在这里我们借助 Scrapy Shell 来模拟 Scrapy 请求的过程,来讲解相关的提取方法。
我们用官方文档的一个样例页面来做演示:http://doc.scrapy.org/en/latest/_static/selectors-sample1.html。
开启 Scrapy Shell,在命令行中输入如下命令:
scrapy shell http://doc.scrapy.org/en/latest/_static/selectors-sample1.html
这样我们就进入了 Scrapy Shell 模式。这个过程其实是 Scrapy 发起了一次请求,请求的 URL 就是刚才命令行下输入的 URL,然后把一些可操作的变量传递给我们,如 request、response 等,如图所示。
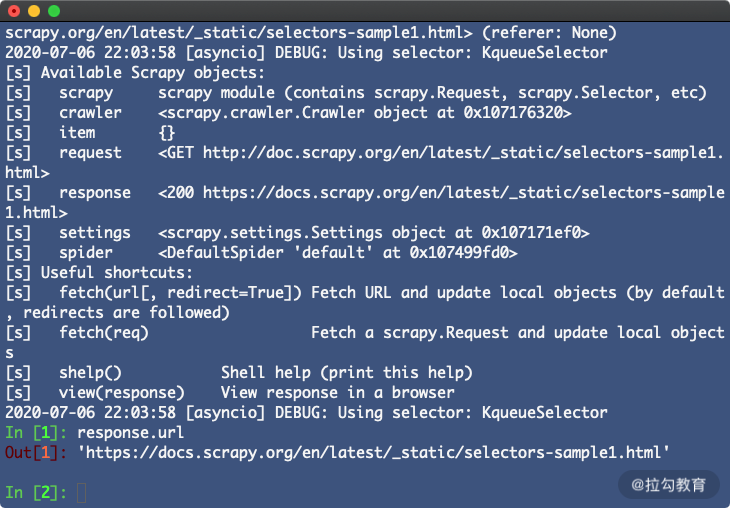
我们可以在命令行模式下输入命令调用对象的一些操作方法,回车之后实时显示结果。这与 Python 的命令行交互模式是类似的。
接下来,演示的实例都将页面的源码作为分析目标,页面源码如下所示:
<html>
<head>
<base href='http://example.com/' />
<title>Example website</title>
</head>
<body>
<div id='images'>
<a href='image1.html'>Name: My image 1 <br /><img src='image1_thumb.jpg' /></a>
<a href='image2.html'>Name: My image 2 <br /><img src='image2_thumb.jpg' /></a>
<a href='image3.html'>Name: My image 3 <br /><img src='image3_thumb.jpg' /></a>
<a href='image4.html'>Name: My image 4 <br /><img src='image4_thumb.jpg' /></a>
<a href='image5.html'>Name: My image 5 <br /><img src='image5_thumb.jpg' /></a>
</div>
</body>
</html>
XPath 选择器
进入 Scrapy Shell 之后,我们将主要操作 response 变量来进行解析。因为我们解析的是 HTML 代码,Selector 将自动使用 HTML 语法来分析。
response 有一个属性 selector,我们调用 response.selector 返回的内容就相当于用 response 的 text 构造了一个 Selector 对象。通过这个 Selector 对象我们可以调用解析方法如 xpath、css 等,通过向方法传入 XPath 或 CSS 选择器参数就可以实现信息的提取。
我们用一个实例感受一下,如下所示:
>>> result = response.selector.xpath('//a')
>>> result
[<Selector xpath='//a' data='<a href="image1.html">Name: My image 1 <'>,
<Selector xpath='//a' data='<a href="image2.html">Name: My image 2 <'>,
<Selector xpath='//a' data='<a href="image3.html">Name: My image 3 <'>,
<Selector xpath='//a' data='<a href="image4.html">Name: My image 4 <'>,
<Selector xpath='//a' data='<a href="image5.html">Name: My image 5 <'>]
>>> type(result)
scrapy.selector.unified.SelectorList
打印结果的形式是 Selector 组成的列表,其实它是 SelectorList 类型,SelectorList 和 Selector 都可以继续调用 xpath 和 css 等方法来进一步提取数据。
在上面的例子中,我们提取了 a 节点。接下来,我们尝试继续调用 xpath 方法来提取 a 节点内包含的 img 节点,如下所示:
>>> result.xpath('./img')
[<Selector xpath='./img' data='<img src="image1_thumb.jpg">'>,
<Selector xpath='./img' data='<img src="image2_thumb.jpg">'>,
<Selector xpath='./img' data='<img src="image3_thumb.jpg">'>,
<Selector xpath='./img' data='<img src="image4_thumb.jpg">'>,
<Selector xpath='./img' data='<img src="image5_thumb.jpg">'>]
我们获得了 a 节点里面的所有 img 节点,结果为 5。
值得注意的是,选择器的最前方加 .(点),这代表提取元素内部的数据,如果没有加点,则代表从根节点开始提取。此处我们用了 ./img 的提取方式,则代表从 a 节点里进行提取。如果此处我们用 //img,则还是从 html 节点里进行提取。
我们刚才使用了 response.selector.xpath 方法对数据进行了提取。Scrapy 提供了两个实用的快捷方法,response.xpath 和 response.css,它们二者的功能完全等同于 response.selector.xpath 和 response.selector.css。方便起见,后面我们统一直接调用 response 的 xpath 和 css 方法进行选择。
现在我们得到的是 SelectorList 类型的变量,该变量是由 Selector 对象组成的列表。我们可以用索引单独取出其中某个 Selector 元素,如下所示:
>>> result[0]
<Selector xpath='//a' data='<a href="image1.html">Name: My image 1 <'>
我们可以像操作列表一样操作这个 SelectorList。但是现在获取的内容是 Selector 或者 SelectorList 类型,并不是真正的文本内容。那么具体的内容怎么提取呢?
比如我们现在想提取出 a 节点元素,就可以利用 extract 方法,如下所示:
>>> result.extract()
['<a href="image1.html">Name: My image 1 <br><img src="image1_thumb.jpg"></a>', '<a href="image2.html">Name: My image 2 <br><img src="image2_thumb.jpg"></a>', '<a href="image3.html">Name: My image 3 <br><img src="image3_thumb.jpg"></a>', '<a href="image4.html">Name: My image 4 <br><img src="image4_thumb.jpg"></a>', '<a href="image5.html">Name: My image 5 <br><img src="image5_thumb.jpg"></a>']
这里使用了 extract 方法,我们就可以把真实需要的内容获取下来。
我们还可以改写 XPath 表达式,来选取节点的内部文本和属性,如下所示:
>>> response.xpath('//a/text()').extract()
['Name: My image 1 ', 'Name: My image 2 ', 'Name: My image 3 ', 'Name: My image 4 ', 'Name: My image 5 ']
>>> response.xpath('//a/@href').extract()
['image1.html', 'image2.html', 'image3.html', 'image4.html', 'image5.html']
我们只需要再加一层 /text() 就可以获取节点的内部文本,或者加一层 /@href 就可以获取节点的 href 属性。其中,@ 符号后面内容就是要获取的属性名称。
现在我们可以用一个规则把所有符合要求的节点都获取下来,返回的类型是列表类型。
但是这里有一个问题:如果符合要求的节点只有一个,那么返回的结果会是什么呢?我们再用一个实例来感受一下,如下所示:
>>> response.xpath('//a[@href="image1.html"]/text()').extract()
['Name: My image 1 ']
我们用属性限制了匹配的范围,使 XPath 只可以匹配到一个元素。然后用 extract 方法提取结果,其结果还是一个列表形式,其文本是列表的第一个元素。但很多情况下,我们其实想要的数据就是第一个元素内容,这里我们通过加一个索引来获取,如下所示:
'Name: My image 1 '
但是,这个写法很明显是有风险的。一旦 XPath 有问题,那么 extract 后的结果可能是一个空列表。如果我们再用索引来获取,那不就可能会导致数组越界吗?
所以,另外一个方法可以专门提取单个元素,它叫作 extract_first。我们可以改写上面的例子如下所示:
>>> response.xpath('//a[@href="image1.html"]/text()').extract_first()
'Name: My image 1 '
这样,我们直接利用 extract_first 方法将匹配的第一个结果提取出来,同时我们也不用担心数组越界的问题。
另外我们也可以为 extract_first 方法设置一个默认值参数,这样当 XPath 规则提取不到内容时会直接使用默认值。例如将 XPath 改成一个不存在的规则,重新执行代码,如下所示:
>>> response.xpath('//a[@href="image1"]/text()').extract_first()>>> response.xpath('//a[@href="image1"]/text()').extract_first('Default Image')
'Default Image'
这里,如果 XPath 匹配不到任何元素,调用 extract_first 会返回空,也不会报错。在第二行代码中,我们还传递了一个参数当作默认值,如 Default Image。这样如果 XPath 匹配不到结果的话,返回值会使用这个参数来代替,可以看到输出正是如此。
到现在为止,我们了解了 Scrapy 中的 XPath 的相关用法,包括嵌套查询、提取内容、提取单个内容、获取文本和属性等。
CSS 选择器
接下来,我们看看 CSS 选择器的用法。Scrapy 的选择器同时还对接了 CSS 选择器,使用 response.css() 方法可以使用 CSS 选择器来选择对应的元素。
例如在上文我们选取了所有的 a 节点,那么 CSS 选择器同样可以做到,如下所示:
>>> response.css('a')
[<Selector xpath='descendant-or-self::a' data='<a href="image1.html">Name: My image 1 <'>,
<Selector xpath='descendant-or-self::a' data='<a href="image2.html">Name: My image 2 <'>,
<Selector xpath='descendant-or-self::a' data='<a href="image3.html">Name: My image 3 <'>,
<Selector xpath='descendant-or-self::a' data='<a href="image4.html">Name: My image 4 <'>,
<Selector xpath='descendant-or-self::a' data='<a href="image5.html">Name: My image 5 <'>]
同样,调用 extract 方法就可以提取出节点,如下所示:
['<a href="image1.html">Name: My image 1 <br><img src="image1_thumb.jpg"></a>', '<a href="image2.html">Name: My image 2 <br><img src="image2_thumb.jpg"></a>', '<a href="image3.html">Name: My image 3 <br><img src="image3_thumb.jpg"></a>', '<a href="image4.html">Name: My image 4 <br><img src="image4_thumb.jpg"></a>', '<a href="image5.html">Name: My image 5 <br><img src="image5_thumb.jpg"></a>']
用法和 XPath 选择是完全一样的。另外,我们也可以进行属性选择和嵌套选择,如下所示:
>>> response.css('a[href="image1.html"]').extract()
['<a href="image1.html">Name: My image 1 <br><img src="image1_thumb.jpg"></a>']
>>> response.css('a[href="image1.html"] img').extract()
['<img src="image1_thumb.jpg">']
这里用 [href="image.html"] 限定了 href 属性,可以看到匹配结果就只有一个了。另外如果想查找 a 节点内的 img 节点,只需要再加一个空格和 img 即可。选择器的写法和标准 CSS 选择器写法如出一辙。
我们也可以使用 extract_first() 方法提取列表的第一个元素,如下所示:
>>> response.css('a[href="image1.html"] img').extract_first()
'<img src="image1_thumb.jpg">'
接下来的两个用法不太一样。节点的内部文本和属性的获取是这样实现的,如下所示:
>>> response.css('a[href="image1.html"]::text').extract_first()
'Name: My image 1 '
>>> response.css('a[href="image1.html"] img::attr(src)').extract_first()
'image1_thumb.jpg'
获取文本和属性需要用 ::text 和 ::attr() 的写法。而其他库如 Beautiful Soup 或 PyQuery 都有单独的方法。
另外,CSS 选择器和 XPath 选择器一样可以嵌套选择。我们可以先用 XPath 选择器选中所有 a 节点,再利用 CSS 选择器选中 img 节点,再用 XPath 选择器获取属性。我们用一个实例来感受一下,如下所示:
>>> response.xpath('//a').css('img').xpath('@src').extract()
['image1_thumb.jpg', 'image2_thumb.jpg', 'image3_thumb.jpg', 'image4_thumb.jpg', 'image5_thumb.jpg']
我们成功获取了所有 img 节点的 src 属性。
因此,我们可以随意使用 xpath 和 css 方法二者自由组合实现嵌套查询,二者是完全兼容的。
正则匹配
Scrapy 的选择器还支持正则匹配。比如,在示例的 a 节点中的文本类似于 Name: My image 1,现在我们只想把 Name: 后面的内容提取出来,这时就可以借助 re 方法,实现如下:
>>> response.xpath('//a/text()').re('Name:\s(.*)')
['My image 1 ', 'My image 2 ', 'My image 3 ', 'My image 4 ', 'My image 5 ']
我们给 re 方法传入一个正则表达式,其中 (.*) 就是要匹配的内容,输出的结果就是正则表达式匹配的分组,结果会依次输出。
如果同时存在两个分组,那么结果依然会被按序输出,如下所示:
>>> response.xpath('//a/text()').re('(.*?):\s(.*)')
['Name', 'My image 1 ', 'Name', 'My image 2 ', 'Name', 'My image 3 ', 'Name', 'My image 4 ', 'Name', 'My image 5 ']
类似 extract_first 方法,re_first 方法可以选取列表的第一个元素,用法如下:
>>> response.xpath('//a/text()').re_first('(.*?):\s(.*)')
'Name'
>>> response.xpath('//a/text()').re_first('Name:\s(.*)')
'My image 1 '
不论正则匹配了几个分组,结果都会等于列表的第一个元素。
值得注意的是,response 对象不能直接调用 re 和 re_first 方法。如果想要对全文进行正则匹配,可以先调用 xpath 方法然后再进行正则匹配,如下所示:
>>> response.re('Name:\s(.*)')
Traceback (most recent call last):
File "<console>", line 1, in <module>
AttributeError: 'HtmlResponse' object has no attribute 're'
>>> response.xpath('.').re('Name:\s(.*)<br>')
['My image 1 ', 'My image 2 ', 'My image 3 ', 'My image 4 ', 'My image 5 ']
>>> response.xpath('.').re_first('Name:\s(.*)<br>')
'My image 1 '
通过上面的例子,我们可以看到,直接调用 re 方法会提示没有 re 属性。但是这里首先调用了 xpath('.')选中全文,然后调用 re 和 re_first 方法,就可以进行正则匹配了。
以上内容便是 Scrapy 选择器的用法,它包括两个常用选择器和正则匹配功能。如果你熟练掌握 XPath 语法、CSS 选择器语法、正则表达式语法可以大大提高数据提取效率。
功能强大的Middleware的用法
我们在 Scrapy 架构中,可以看到有一个叫作 Middleware 的概念,中文翻译过来就叫作中间件,在 Scrapy 中有两种 Middleware,一种是 Spider Middleware,另一种是 Downloader Middleware,本节课我们分别来介绍下。
Spider Middleware 的用法
Spider Middleware 是介入 Scrapy 的 Spider 处理机制的钩子框架。
当 Downloader 生成 Response 之后,Response 会被发送给 Spider,在发送给 Spider 之前,Response 会首先经过 Spider Middleware 处理,当 Spider 处理生成 Item 和 Request 之后,Item 和 Request 还会经过 Spider Middleware 的处理。
Spider Middleware 有如下三个作用。
-
我们可以在 Downloader 生成的 Response 发送给 Spider 之前,也就是在 Response 发送给 Spider 之前对 Response 进行处理。
-
我们可以在 Spider 生成的 Request 发送给 Scheduler 之前,也就是在 Request 发送给 Scheduler 之前对 Request 进行处理。
-
我们可以在 Spider 生成的 Item 发送给 Item Pipeline 之前,也就是在 Item 发送给 Item Pipeline 之前对 Item 进行处理。
使用说明
需要说明的是,Scrapy 其实已经提供了许多 Spider Middleware,它们被 SPIDER_MIDDLEWARES_BASE 这个变量所定义。
SPIDER_MIDDLEWARES_BASE 变量的内容如下:
{
'scrapy.spidermiddlewares.httperror.HttpErrorMiddleware': 50,
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware': 500,
'scrapy.spidermiddlewares.referer.RefererMiddleware': 700,
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware': 800,
'scrapy.spidermiddlewares.depth.DepthMiddleware': 900,
}
和 Downloader Middleware 一样,Spider Middleware 首先加入 SPIDER_MIDDLEWARES 的设置中,该设置会和 Scrapy 中 SPIDER_MIDDLEWARES_BASE 定义的 Spider Middleware 合并。然后根据键值的数字优先级排序,得到一个有序列表。第一个 Middleware 是最靠近引擎的,最后一个 Middleware 是最靠近 Spider 的。
核心方法
Scrapy 内置的 Spider Middleware 为 Scrapy 提供了基础的功能。如果我们想要扩展其功能,只需要实现某几个方法即可。
每个 Spider Middleware 都定义了以下一个或多个方法的类,核心方法有如下 4 个。
-
process_spider_input(response, spider)
-
process_spider_output(response, result, spider)
-
process_spider_exception(response, exception, spider)
-
process_start_requests(start_requests, spider)
只需要实现其中一个方法就可以定义一个 Spider Middleware。下面我们来看看这 4 个方法的详细用法。
process_spider_input(response, spider)
当 Response 通过 Spider Middleware 时,该方法被调用,处理该 Response。
方法的参数有两个:
-
response,即 Response 对象,即被处理的 Response;
-
spider,即 Spider 对象,即该 response 对应的 Spider。
process_spider_input() 应该返回 None 或者抛出一个异常。
-
如果其返回 None,Scrapy 将会继续处理该 Response,调用所有其他的 Spider Middleware 直到 Spider 处理该 Response。
-
如果其抛出一个异常,Scrapy 将不会调用任何其他 Spider Middleware 的 process_spider_input() 方法,并调用 Request 的 errback() 方法。 errback 的输出将会以另一个方向被重新输入到中间件中,使用 process_spider_output() 方法来处理,当其抛出异常时则调用 process_spider_exception() 来处理。
process_spider_output(response, result, spider)
当 Spider 处理 Response 返回结果时,该方法被调用。
方法的参数有三个:
-
response,即 Response 对象,即生成该输出的 Response;
-
result,包含 Request 或 Item 对象的可迭代对象,即 Spider 返回的结果;
-
spider,即 Spider 对象,即其结果对应的 Spider。
process_spider_output() 必须返回包含 Request 或 Item 对象的可迭代对象。
process_spider_exception(response, exception, spider)
当 Spider 或 Spider Middleware 的 process_spider_input() 方法抛出异常时, 该方法被调用。
方法的参数有三个:
-
response,即 Response 对象,即异常被抛出时被处理的 Response;
-
exception,即 Exception 对象,被抛出的异常;
-
spider,即 Spider 对象,即抛出该异常的 Spider。
process_spider_exception() 必须返回结果,要么返回 None , 要么返回一个包含 Response 或 Item 对象的可迭代对象。
-
如果其返回 None ,Scrapy 将继续处理该异常,调用其他 Spider Middleware 中的 process_spider_exception() 方法,直到所有 Spider Middleware 都被调用。
-
如果其返回一个可迭代对象,则其他 Spider Middleware 的 process_spider_output() 方法被调用, 其他的 process_spider_exception() 将不会被调用。
process_start_requests(start_requests, spider)
该方法以 Spider 启动的 Request 为参数被调用,执行的过程类似于 process_spider_output() ,只不过其没有相关联的 Response 并且必须返回 Request。
方法的参数有两个:
-
start_requests,即包含 Request 的可迭代对象,即 Start Requests;
-
spider,即 Spider 对象,即 Start Requests 所属的 Spider。
其必须返回另一个包含 Request 对象的可迭代对象。
Downloader Middleware 的用法
Downloader Middleware 即下载中间件,它是处于 Scrapy 的 Request 和 Response 之间的处理模块。
Scheduler 从队列中拿出一个 Request 发送给 Downloader 执行下载,这个过程会经过 Downloader Middleware 的处理。另外,当 Downloader 将 Request 下载完成得到 Response 返回给 Spider 时会再次经过 Downloader Middleware 处理。
也就是说,Downloader Middleware 在整个架构中起作用的位置是以下两个。
-
在 Scheduler 调度出队列的 Request 发送给 Downloader 下载之前,也就是我们可以在 Request 执行下载之前对其进行修改。
-
在下载后生成的 Response 发送给 Spider 之前,也就是我们可以在生成 Resposne 被 Spider 解析之前对其进行修改。
Downloader Middleware 的功能十分强大,修改 User-Agent、处理重定向、设置代理、失败重试、设置 Cookies 等功能都需要借助它来实现。下面我们来了解一下 Downloader Middleware 的详细用法。
使用说明
需要说明的是,Scrapy 其实已经提供了许多 Downloader Middleware,比如负责失败重试、自动重定向等功能的 Middleware,它们被 DOWNLOADER_MIDDLEWARES_BASE 变量所定义。
DOWNLOADER_MIDDLEWARES_BASE 变量的内容如下所示:
{
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100,
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': 300,
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware': 350,
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 400,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 500,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware': 560,
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': 580,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 590,
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 600,
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750,
'scrapy.downloadermiddlewares.stats.DownloaderStats': 850,
'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': 900,
}
这是一个字典格式,字典的键名是 Scrapy 内置的 Downloader Middleware 的名称,键值代表了调用的优先级,优先级是一个数字,数字越小代表越靠近 Scrapy 引擎,数字越大代表越靠近 Downloader。每个 Downloader Middleware 都可以定义 process_request() 和 request_response() 方法来分别处理请求和响应,对于 process_request() 方法来说,优先级数字越小越先被调用,对于 process_response() 方法来说,优先级数字越大越先被调用。
如果自己定义的 Downloader Middleware 要添加到项目里,DOWNLOADER_MIDDLEWARES_BASE 变量不能直接修改。Scrapy 提供了另外一个设置变量 DOWNLOADER_MIDDLEWARES,我们直接修改这个变量就可以添加自己定义的 Downloader Middleware,以及禁用 DOWNLOADER_MIDDLEWARES_BASE 里面定义的 Downloader Middleware。下面我们具体来看看 Downloader Middleware 的使用方法。
核心方法
Scrapy 内置的 Downloader Middleware 为 Scrapy 提供了基础的功能,但在项目实战中我们往往需要单独定义 Downloader Middleware。不用担心,这个过程非常简单,我们只需要实现某几个方法即可。
每个 Downloader Middleware 都定义了一个或多个方法的类,核心的方法有如下三个。
-
process_request(request, spider)
-
process_response(request, response, spider)
-
process_exception(request, exception, spider)
我们只需要实现至少一个方法,就可以定义一个 Downloader Middleware。下面我们来看看这三个方法的详细用法。
process_request(request, spider)
Request 被 Scrapy 引擎调度给 Downloader 之前,process_request() 方法就会被调用,也就是在 Request 从队列里调度出来到 Downloader 下载执行之前,我们都可以用 process_request() 方法对 Request 进行处理。方法的返回值必须为 None、Response 对象、Request 对象之一,或者抛出 IgnoreRequest 异常。
process_request() 方法的参数有如下两个。
-
request,即 Request 对象,即被处理的 Request;
-
spider,即 Spider 对象,即此 Request 对应的 Spider。
返回类型不同,产生的效果也不同。下面归纳一下不同的返回情况。
-
当返回为 None 时,Scrapy 将继续处理该 Request,接着执行其他 Downloader Middleware 的 process_request() 方法,直到 Downloader 把 Request 执行后得到 Response 才结束。这个过程其实就是修改 Request 的过程,不同的 Downloader Middleware 按照设置的优先级顺序依次对 Request 进行修改,最后推送至 Downloader 执行。
-
当返回为 Response 对象时,更低优先级的 Downloader Middleware 的 process_request() 和 process_exception() 方法就不会被继续调用,每个 Downloader Middleware 的 process_response() 方法转而被依次调用。调用完毕之后,直接将 Response 对象发送给 Spider 来处理。
-
当返回为 Request 对象时,更低优先级的 Downloader Middleware 的 process_request() 方法会停止执行。这个 Request 会重新放到调度队列里,其实它就是一个全新的 Request,等待被调度。如果被 Scheduler 调度了,那么所有的 Downloader Middleware 的 process_request() 方法会被重新按照顺序执行。
-
如果 IgnoreRequest 异常抛出,则所有的 Downloader Middleware 的 process_exception() 方法会依次执行。如果没有一个方法处理这个异常,那么 Request 的 errorback() 方法就会回调。如果该异常还没有被处理,那么它便会被忽略。
process_response(request, response, spider)
Downloader 执行 Request 下载之后,会得到对应的 Response。Scrapy 引擎便会将 Response 发送给 Spider 进行解析。在发送之前,我们都可以用 process_response() 方法来对 Response 进行处理。方法的返回值必须为 Request 对象、Response 对象之一,或者抛出 IgnoreRequest 异常。
process_response() 方法的参数有如下三个。
-
request,是 Request 对象,即此 Response 对应的 Request。
-
response,是 Response 对象,即此被处理的 Response。
-
spider,是 Spider 对象,即此 Response 对应的 Spider。
下面对不同的返回情况做一下归纳:
-
当返回为 Request 对象时,更低优先级的 Downloader Middleware 的 process_response() 方法不会继续调用。该 Request 对象会重新放到调度队列里等待被调度,它相当于一个全新的 Request。然后,该 Request 会被 process_request() 方法顺次处理。
-
当返回为 Response 对象时,更低优先级的 Downloader Middleware 的 process_response() 方法会继续调用,继续对该 Response 对象进行处理。
-
如果 IgnoreRequest 异常抛出,则 Request 的 errorback() 方法会回调。如果该异常还没有被处理,那么它便会被忽略。
process_exception(request, exception, spider)
当 Downloader 或 process_request() 方法抛出异常时,例如抛出 IgnoreRequest 异常,process_exception() 方法就会被调用。方法的返回值必须为 None、Response 对象、Request 对象之一。
process_exception() 方法的参数有如下三个。
-
request,即 Request 对象,即产生异常的 Request。
-
exception,即 Exception 对象,即抛出的异常。
-
spdier,即 Spider 对象,即 Request 对应的 Spider。
下面归纳一下不同的返回值。
-
当返回为 None 时,更低优先级的 Downloader Middleware 的 process_exception() 会被继续顺次调用,直到所有的方法都被调度完毕。
-
当返回为 Response 对象时,更低优先级的 Downloader Middleware 的 process_exception() 方法不再被继续调用,每个 Downloader Middleware 的 process_response() 方法转而被依次调用。
-
当返回为 Request 对象时,更低优先级的 Downloader Middleware 的 process_exception() 也不再被继续调用,该 Request 对象会重新放到调度队列里面等待被调度,它相当于一个全新的 Request。然后,该 Request 又会被 process_request() 方法顺次处理。
以上内容便是这三个方法的详细使用逻辑。在使用它们之前,请先对这三个方法的返回值的处理情况有一个清晰的认识。在自定义 Downloader Middleware 的时候,也一定要注意每个方法的返回类型。
下面我们用一个案例实战来加深一下对 Downloader Middleware 用法的理解。
项目实战
新建一个项目,命令如下所示:
scrapy startproject scrapydownloadertest
新建了一个 Scrapy 项目,名为 scrapydownloadertest。进入项目,新建一个 Spider,命令如下所示:
scrapy genspider httpbin httpbin.org
新建了一个 Spider,名为 httpbin,源代码如下所示:
import scrapy
class HttpbinSpider(scrapy.Spider):
name = 'httpbin'
allowed_domains = ['httpbin.org']
start_urls = ['http://httpbin.org/']
def parse(self, response):
pass
接下来我们修改 start_urls 为:['http://httpbin.org/']。随后将 parse() 方法添加一行日志输出,将 response 变量的 text 属性输出,这样我们便可以看到 Scrapy 发送的 Request 信息了。
修改 Spider 内容如下所示:
import scrapy
class HttpbinSpider(scrapy.Spider):
name = 'httpbin'
allowed_domains = ['httpbin.org']
start_urls = ['http://httpbin.org/get']
def parse(self, response):
self.logger.debug(response.text)
接下来运行此 Spider,执行如下命令:
scrapy crawl httpbin
Scrapy 运行结果包含 Scrapy 发送的 Request 信息,内容如下所示:
{"args": {},
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "gzip,deflate,br",
"Accept-Language": "en",
"Connection": "close",
"Host": "httpbin.org",
"User-Agent": "Scrapy/1.4.0 (+http://scrapy.org)"
},
"origin": "60.207.237.85",
"url": "http://httpbin.org/get"
}
我们观察一下 Headers,Scrapy 发送的 Request 使用的 User-Agent 是 Scrapy/1.4.0(+http://scrapy.org),这其实是由 Scrapy 内置的 UserAgentMiddleware 设置的,UserAgentMiddleware 的源码如下所示:
from scrapy import signals
class UserAgentMiddleware(object):
def __init__(self, user_agent='Scrapy'):
self.user_agent = user_agent
@classmethod
def from_crawler(cls, crawler):
o = cls(crawler.settings['USER_AGENT'])
crawler.signals.connect(o.spider_opened, signal=signals.spider_opened)
return o
def spider_opened(self, spider):
self.user_agent = getattr(spider, 'user_agent', self.user_agent)
def process_request(self, request, spider):
if self.user_agent:
request.headers.setdefault(b'User-Agent', self.user_agent)
在 from_crawler() 方法中,首先尝试获取 settings 里面的 USER_AGENT,然后把 USER_AGENT 传递给 init() 方法进行初始化,其参数就是 user_agent。如果没有传递 USER_AGENT 参数就默认设置为 Scrapy 字符串。我们新建的项目没有设置 USER_AGENT,所以这里的 user_agent 变量就是 Scrapy。接下来,在 process_request() 方法中,将 user-agent 变量设置为 headers 变量的一个属性,这样就成功设置了 User-Agent。因此,User-Agent 就是通过此 Downloader Middleware 的 process_request() 方法设置的。
修改请求时的 User-Agent 可以有两种方式:一是修改 settings 里面的 USER_AGENT 变量;二是通过 Downloader Middleware 的 process_request() 方法来修改。
第一种方法非常简单,我们只需要在 setting.py 里面加一行 USER_AGENT 的定义即可:
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
一般推荐使用此方法来设置。但是如果想设置得更灵活,比如设置随机的 User-Agent,那就需要借助 Downloader Middleware 了。所以接下来我们用 Downloader Middleware 实现一个随机 User-Agent 的设置。
在 middlewares.py 里面添加一个 RandomUserAgentMiddleware 的类,如下所示:
import random
class RandomUserAgentMiddleware():
def __init__(self):
self.user_agents = ['Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.2 (KHTML, like Gecko) Chrome/22.0.1216.0 Safari/537.2',
'Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:15.0) Gecko/20100101 Firefox/15.0.1'
]
def process_request(self, request, spider):
request.headers['User-Agent'] = random.choice(self.user_agents)
我们首先在类的 __init__() 方法中定义了三个不同的 User-Agent,并用一个列表来表示。接下来实现了 process_request() 方法,它有一个参数 request,我们直接修改 request 的属性即可。在这里我们直接设置了 request 对象的 headers 属性的 User-Agent,设置内容是随机选择的 User-Agent,这样一个 Downloader Middleware 就写好了。
不过,要使之生效我们还需要再去调用这个 Downloader Middleware。在 settings.py 中,将 DOWNLOADER_MIDDLEWARES 取消注释,并设置成如下内容:
DOWNLOADER_MIDDLEWARES = {'scrapydownloadertest.middlewares.RandomUserAgentMiddleware': 543,}
接下来我们重新运行 Spider,就可以看到 User-Agent 被成功修改为列表中所定义的随机的一个 User-Agent 了:
{"args": {},
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "gzip,deflate,br",
"Accept-Language": "en",
"Connection": "close",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)"
},
"origin": "60.207.237.85",
"url": "http://httpbin.org/get"
}
我们就通过实现 Downloader Middleware 并利用 process_request() 方法成功设置了随机的 User-Agent。
另外,Downloader Middleware 还有 process_response() 方法。Downloader 对 Request 执行下载之后会得到 Response,随后 Scrapy 引擎会将 Response 发送回 Spider 进行处理。但是在 Response 被发送给 Spider 之前,我们同样可以使用 process_response() 方法对 Response 进行处理。比如这里修改一下 Response 的状态码,在 RandomUserAgentMiddleware 添加如下代码:
def process_response(self, request, response, spider):
response.status = 201
return response
我们将 response 对象的 status 属性修改为 201,随后将 response 返回,这个被修改后的 Response 就会被发送到 Spider。
我们再在 Spider 里面输出修改后的状态码,在 parse() 方法中添加如下的输出语句:
self.logger.debug('Status Code: ' + str(response.status))
重新运行之后,控制台输出了如下内容:
[httpbin] DEBUG: Status Code: 201
可以发现,Response 的状态码成功修改了。因此要想对 Response 进行处理,就可以借助于 process_response() 方法。
另外还有一个 process_exception() 方法,它是用来处理异常的方法。如果需要异常处理的话,我们可以调用此方法。不过这个方法的使用频率相对低一些,在此不用实例演示。
本节代码
本节源代码为:
https://github.com/Python3WebSpider/ScrapyDownloaderTest。
结语
本节讲解了 Spider Middleware 和 Downloader Middleware 的基本用法。利用它们我们可以方便地实现爬虫逻辑的灵活处理,需要好好掌握。
哪都能存,Item Pipeline的用法
在前面的示例中我们已经了解了 Item Pipeline 项目管道的基本概念,本节课我们就深入详细讲解它的用法。
首先我们看看 Item Pipeline 在 Scrapy 中的架构,如图所示。
图中的最左侧即为 Item Pipeline,它的调用发生在 Spider 产生 Item 之后。当 Spider 解析完 Response 之后,Item 就会传递到 Item Pipeline,被定义的 Item Pipeline 组件会顺次调用,完成一连串的处理过程,比如数据清洗、存储等。
它的主要功能有:
-
清洗 HTML 数据;
-
验证爬取数据,检查爬取字段;
-
查重并丢弃重复内容;
-
将爬取结果储存到数据库。
1. 核心方法
我们可以自定义 Item Pipeline,只需要实现指定的方法就可以,其中必须要实现的一个方法是:
-
process_item(item, spider)
另外还有几个比较实用的方法,它们分别是:
-
open_spider(spider)
-
close_spider(spider)
-
from_crawler(cls, crawler)
下面我们对这几个方法的用法做下详细的介绍:
process_item(item, spider)
process_item() 是必须要实现的方法,被定义的 Item Pipeline 会默认调用这个方法对 Item 进行处理。比如,我们可以进行数据处理或者将数据写入数据库等操作。它必须返回 Item 类型的值或者抛出一个 DropItem 异常。
process_item() 方法的参数有如下两个:
-
item,是 Item 对象,即被处理的 Item;
-
spider,是 Spider 对象,即生成该 Item 的 Spider。
下面对该方法的返回类型归纳如下:
-
如果返回的是 Item 对象,那么此 Item 会被低优先级的 Item Pipeline 的 process_item() 方法进行处理,直到所有的方法被调用完毕。
-
如果抛出的是 DropItem 异常,那么此 Item 就会被丢弃,不再进行处理。
open_spider(self, spider)
open_spider() 方法是在 Spider 开启的时候被自动调用的,在这里我们可以做一些初始化操作,如开启数据库连接等。其中参数 spider 就是被开启的 Spider 对象。
close_spider(spider)
close_spider() 方法是在 Spider 关闭的时候自动调用的,在这里我们可以做一些收尾工作,如关闭数据库连接等,其中参数 spider 就是被关闭的 Spider 对象。
from_crawler(cls, crawler)
from_crawler() 方法是一个类方法,用 @classmethod 标识,是一种依赖注入的方式。它的参数是 crawler,通过 crawler 对象,我们可以拿到 Scrapy 的所有核心组件,如全局配置的每个信息,然后创建一个 Pipeline 实例。参数 cls 就是 Class,最后返回一个 Class 实例。
下面我们用一个实例来加深对 Item Pipeline 用法的理解。
2. 本节目标
我们以爬取 360 摄影美图为例,来分别实现 MongoDB 存储、MySQL 存储、Image 图片存储的三个 Pipeline。
3. 准备工作
请确保已经安装好 MongoDB 和 MySQL 数据库,安装好 Python 的 PyMongo、PyMySQL、Scrapy 框架,另外需要安装 pillow 图像处理库,如果没有安装可以参考前文的安装说明。
4. 抓取分析
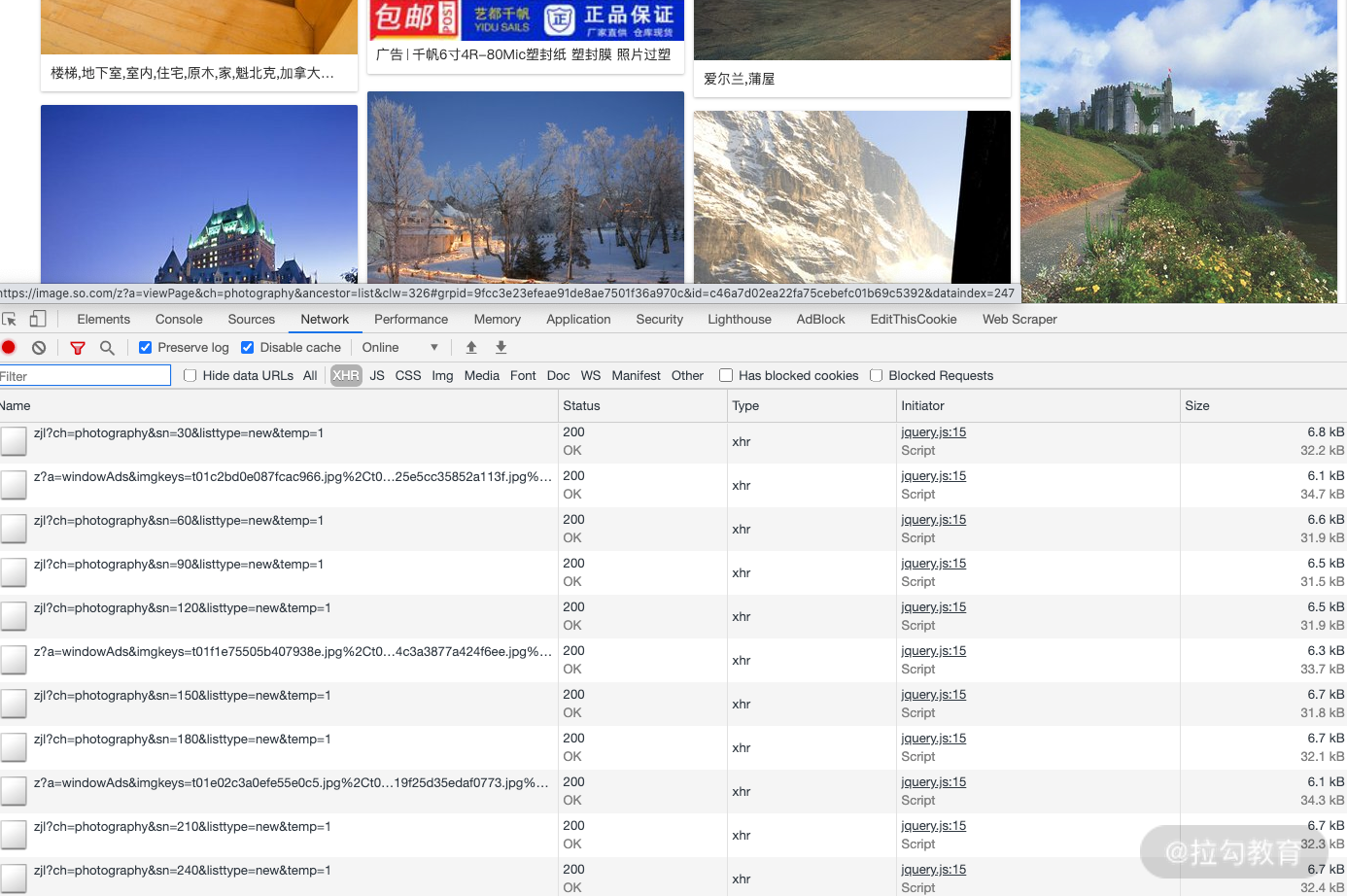
我们这次爬取的目标网站为:https://image.so.com。打开此页面,切换到摄影页面,网页中呈现了许许多多的摄影美图。我们打开浏览器开发者工具,过滤器切换到 XHR 选项,然后下拉页面,可以看到下面就会呈现许多 Ajax 请求,如图所示。
我们查看一个请求的详情,观察返回的数据结构,如图所示。
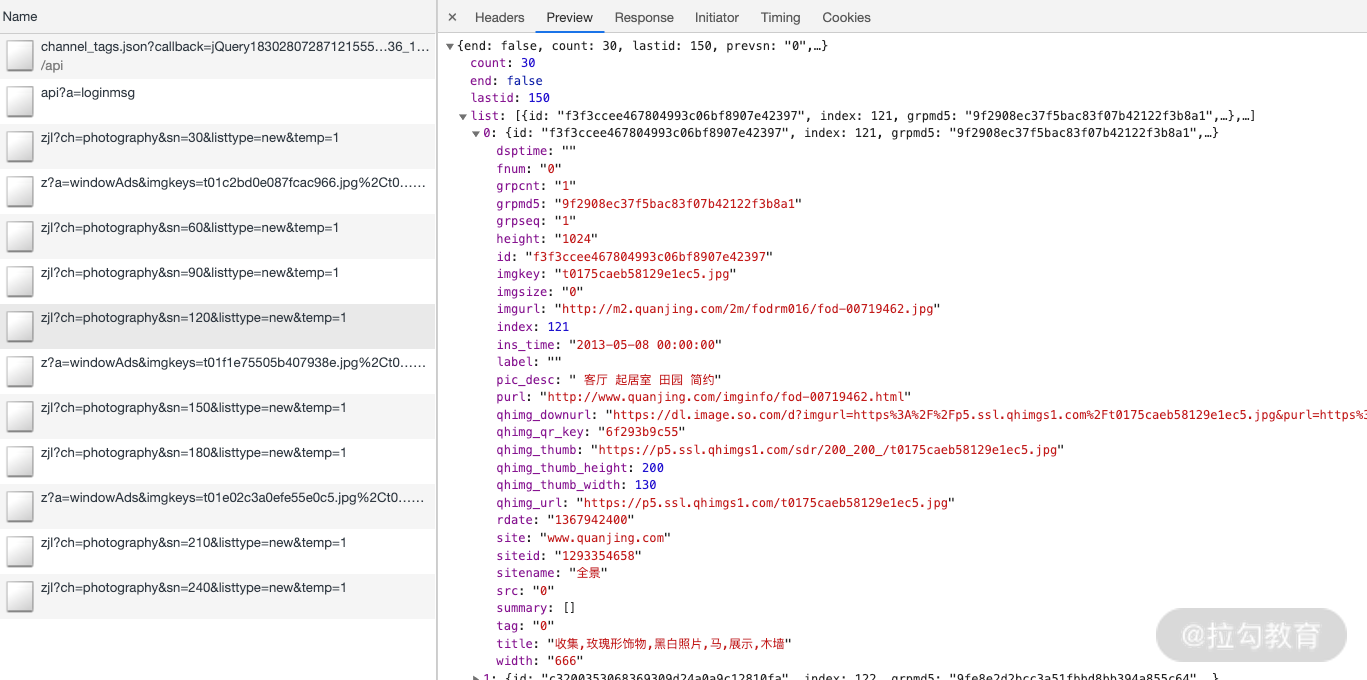
返回格式是 JSON。其中 list 字段就是一张张图片的详情信息,包含了 30 张图片的 ID、名称、链接、缩略图等信息。另外观察 Ajax 请求的参数信息,有一个参数 sn 一直在变化,这个参数很明显就是偏移量。当 sn 为 30 时,返回的是前 30 张图片,sn 为 60 时,返回的就是第 31~60 张图片。另外,ch 参数是摄影类别,listtype 是排序方式,temp 参数可以忽略。
所以我们抓取时只需要改变 sn 的数值就好了。下面我们用 Scrapy 来实现图片的抓取,将图片的信息保存到 MongoDB、MySQL,同时将图片存储到本地。
5. 新建项目
首先新建一个项目,命令如下:
scrapy startproject images360
接下来新建一个 Spider,命令如下:
scrapy genspider images images.so.com
这样我们就成功创建了一个 Spider。
6. 构造请求
接下来定义爬取的页数。比如爬取 50 页、每页 30 张,也就是 1500 张图片,我们可以先在 settings.py 里面定义一个变量 MAX_PAGE,添加如下定义:
MAX_PAGE = 50
定义 start_requests() 方法,用来生成 50 次请求,如下所示:
def start_requests(self):
data = {'ch': 'photography', 'listtype': 'new'}
base_url = 'https://image.so.com/zjl?'
for page in range(1, self.settings.get('MAX_PAGE') + 1):
data['sn'] = page * 30
params = urlencode(data)
url = base_url + params
yield Request(url, self.parse)
在这里我们首先定义了初始的两个参数,sn 参数是遍历循环生成的。然后利用 urlencode 方法将字典转化为 URL 的 GET 参数,构造出完整的 URL,构造并生成 Request。
还需要引入 scrapy.Request 和 urllib.parse 模块,如下所示:
from scrapy import Spider, Request
from urllib.parse import urlencode
再修改 settings.py 中的 ROBOTSTXT_OBEY 变量,将其设置为 False,否则无法抓取,如下所示:
ROBOTSTXT_OBEY = False
运行爬虫,即可以看到链接都请求成功,执行命令如下所示:
scrapy crawl images
运行示例结果如图所示。
所有请求的状态码都是 200,这就证明图片信息爬取成功了。
7. 提取信息
首先定义一个叫作 ImageItem 的 Item,如下所示:
from scrapy import Item, Field
class ImageItem(Item):
collection = table = 'images'
id = Field()
url = Field()
title = Field()
thumb = Field()
在这里我们定义了 4 个字段,包括图片的 ID、链接、标题、缩略图。另外还有两个属性 collection 和 table,都定义为 images 字符串,分别代表 MongoDB 存储的 Collection 名称和 MySQL 存储的表名称。
接下来我们提取 Spider 里有关信息,将 parse 方法改写为如下所示:
def parse(self, response):
result = json.loads(response.text)
for image in result.get('list'):
item = ImageItem()
item['id'] = image.get('id')
item['url'] = image.get('qhimg_url')
item['title'] = image.get('title')
item['thumb'] = image.get('qhimg_thumb')
yield item
首先解析 JSON,遍历其 list 字段,取出一个个图片信息,然后再对 ImageItem 进行赋值,生成 Item 对象。
这样我们就完成了信息的提取。
8. 存储信息
接下来我们需要将图片的信息保存到 MongoDB、MySQL 中,同时将图片保存到本地。
MongoDB
首先确保 MongoDB 已经正常安装并且能够正常运行。
我们用一个 MongoPipeline 将信息保存到 MongoDB 中,在 pipelines.py 里添加如下类的实现:
import pymongo
class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def process_item(self, item, spider):
self.db[item.collection].insert(dict(item))
return item
def close_spider(self, spider):
self.client.close()
这里需要用到两个变量,MONGO_URI 和 MONGO_DB,即存储到 MongoDB 的链接地址和数据库名称。我们在 settings.py 里添加这两个变量,如下所示:
MONGO_URI = 'localhost'
MONGO_DB = 'images360'
这样一个保存到 MongoDB 的 Pipeline 的就创建好了。这里最主要的方法是 process_item(),直接调用 Collection 对象的 insert 方法即可完成数据的插入,最后返回 Item 对象。
MySQL
首先需要确保 MySQL 已经正确安装并且正常运行。
新建一个数据库,名字还是 images360,SQL 语句如下所示:
CREATE DATABASE images360 DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci
新建一个数据表,包含 id、url、title、thumb 四个字段,SQL 语句如下所示:
CREATE TABLE images (id VARCHAR(255) NULL PRIMARY KEY, url VARCHAR(255) NULL , title VARCHAR(255) NULL , thumb VARCHAR(255) NULL)
执行完 SQL 语句之后,我们就成功创建好了数据表。接下来就可以往表里存储数据了。
接下来我们实现一个 MySQLPipeline,代码如下所示:
import pymysql
class MysqlPipeline():
def __init__(self, host, database, user, password, port):
self.host = host
self.database = database
self.user = user
self.password = password
self.port = port
@classmethod
def from_crawler(cls, crawler):
return cls(host=crawler.settings.get('MYSQL_HOST'),
database=crawler.settings.get('MYSQL_DATABASE'),
user=crawler.settings.get('MYSQL_USER'),
password=crawler.settings.get('MYSQL_PASSWORD'),
port=crawler.settings.get('MYSQL_PORT'),
)
def open_spider(self, spider):
self.db = pymysql.connect(self.host, self.user, self.password, self.database, charset='utf8', port=self.port)
self.cursor = self.db.cursor()
def close_spider(self, spider):
self.db.close()
def process_item(self, item, spider):
data = dict(item)
keys = ', '.join(data.keys())
values = ', '.join(['% s'] * len(data))
sql = 'insert into % s (% s) values (% s)' % (item.table, keys, values)
self.cursor.execute(sql, tuple(data.values()))
self.db.commit()
return item
如前所述,这里用到的数据插入方法是一个动态构造 SQL 语句的方法。
这里还需要几个 MySQL 的配置,我们在 settings.py 里添加几个变量,如下所示:
MYSQL_HOST = 'localhost'
MYSQL_DATABASE = 'images360'
MYSQL_PORT = 3306
MYSQL_USER = 'root'
MYSQL_PASSWORD = '123456'
这里分别定义了 MySQL 的地址、数据库名称、端口、用户名、密码。这样,MySQL Pipeline 就完成了。
Image Pipeline
Scrapy 提供了专门处理下载的 Pipeline,包括文件下载和图片下载。下载文件和图片的原理与抓取页面的原理一样,因此下载过程支持异步和多线程,十分高效。下面我们来看看具体的实现过程。
官方文档地址为:https://doc.scrapy.org/en/latest/topics/media-pipeline.html。
首先定义存储文件的路径,需要定义一个 IMAGES_STORE 变量,在 settings.py 中添加如下代码:
IMAGES_STORE = './images'
在这里我们将路径定义为当前路径下的 images 子文件夹,即下载的图片都会保存到本项目的 images 文件夹中。
内置的 ImagesPipeline 会默认读取 Item 的 image_urls 字段,并认为该字段是一个列表形式,它会遍历 Item 的 image_urls 字段,然后取出每个 URL 进行图片下载。
但是现在生成的 Item 的图片链接字段并不是 image_urls 字段表示的,也不是列表形式,而是单个的 URL。所以为了实现下载,我们需要重新定义下载的部分逻辑,即需要自定义 ImagePipeline,继承内置的 ImagesPipeline,重写方法。
我们定义 ImagePipeline,如下所示:
from scrapy import Request
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
class ImagePipeline(ImagesPipeline):
def file_path(self, request, response=None, info=None):
url = request.url
file_name = url.split('/')[-1]
return file_name
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem('Image Downloaded Failed')
return item
def get_media_requests(self, item, info):
yield Request(item['url'])
在这里我们实现了 ImagePipeline,继承 Scrapy 内置的 ImagesPipeline,重写了下面几个方法。
-
get_media_requests()。它的第一个参数 item 是爬取生成的 Item 对象。我们将它的 url 字段取出来,然后直接生成 Request 对象。此 Request 加入调度队列,等待被调度,执行下载。
-
file_path()。它的第一个参数 request 就是当前下载对应的 Request 对象。这个方法用来返回保存的文件名,直接将图片链接的最后一部分当作文件名即可。它利用 split() 函数分割链接并提取最后一部分,返回结果。这样此图片下载之后保存的名称就是该函数返回的文件名。
-
item_completed(),它是当单个 Item 完成下载时的处理方法。因为并不是每张图片都会下载成功,所以我们需要分析下载结果并剔除下载失败的图片。如果某张图片下载失败,那么我们就不需保存此 Item 到数据库。该方法的第一个参数 results 就是该 Item 对应的下载结果,它是一个列表形式,列表每一个元素是一个元组,其中包含了下载成功或失败的信息。这里我们遍历下载结果找出所有成功的下载列表。如果列表为空,那么该 Item 对应的图片下载失败,随即抛出异常 DropItem,该 Item 忽略。否则返回该 Item,说明此 Item 有效。
现在为止,三个 Item Pipeline 的定义就完成了。最后只需要启用就可以了,修改 settings.py,设置 ITEM_PIPELINES,如下所示:
ITEM_PIPELINES = {
'images360.pipelines.ImagePipeline': 300,
'images360.pipelines.MongoPipeline': 301,
'images360.pipelines.MysqlPipeline': 302,
}
这里注意调用的顺序。我们需要优先调用 ImagePipeline 对 Item 做下载后的筛选,下载失败的 Item 就直接忽略,它们就不会保存到 MongoDB 和 MySQL 里。随后再调用其他两个存储的 Pipeline,这样就能确保存入数据库的图片都是下载成功的。
接下来运行程序,执行爬取,如下所示:
scrapy crawl images
爬虫一边爬取一边下载,下载速度非常快,对应的输出日志如图所示。
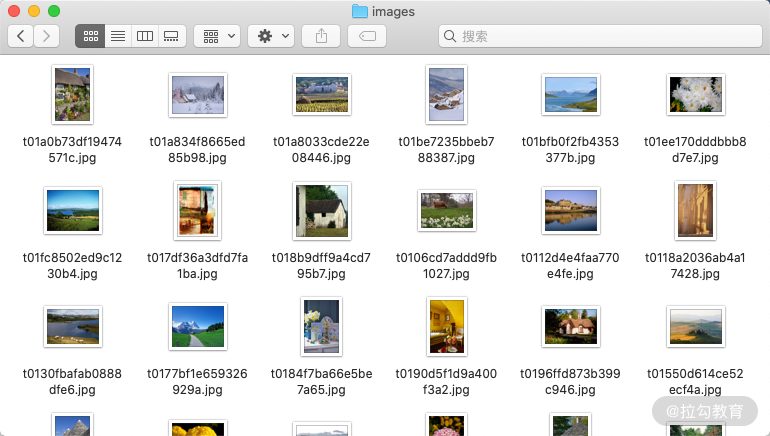
查看本地 images 文件夹,发现图片都已经成功下载,如图所示。
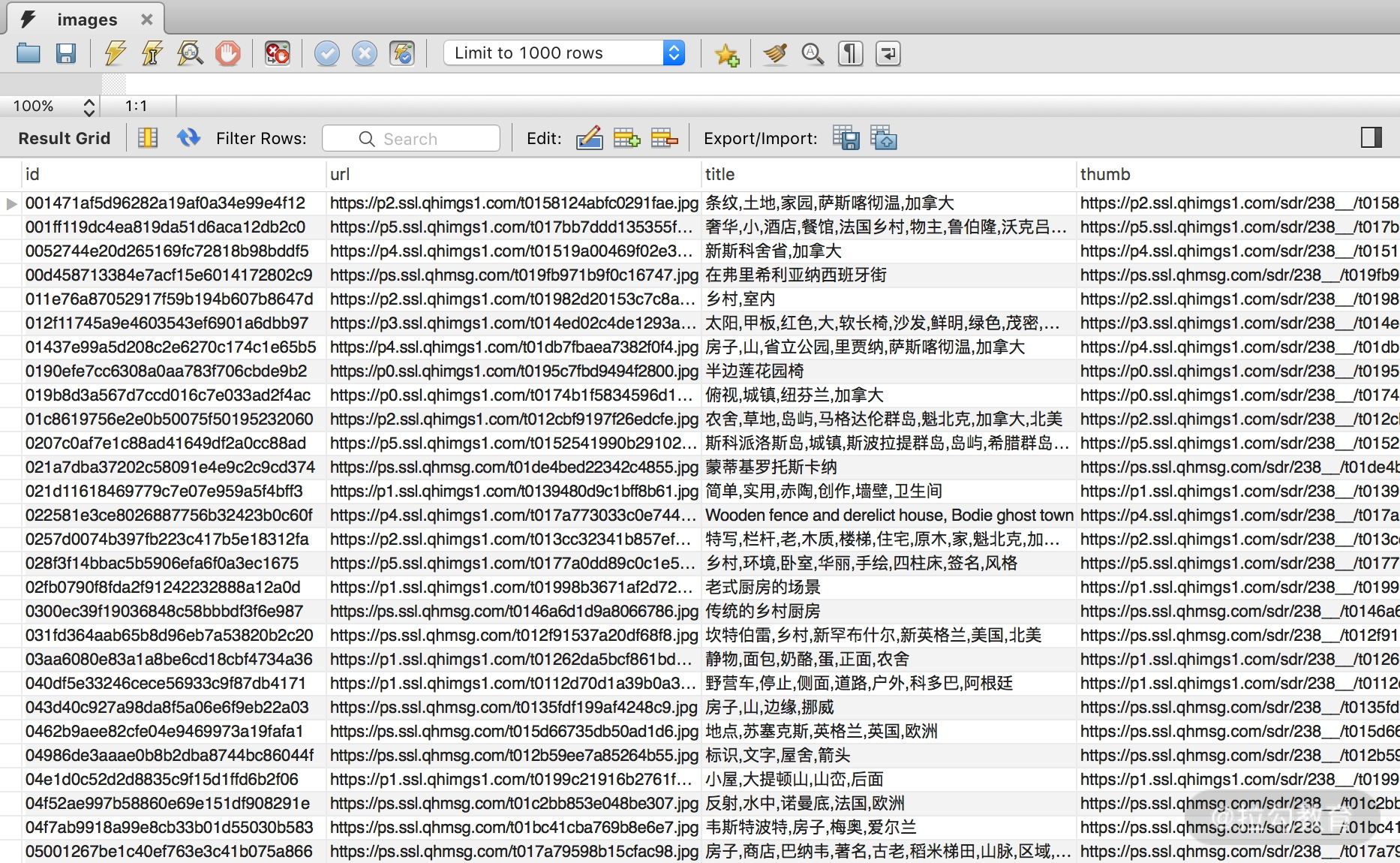
查看 MySQL,下载成功的图片信息也已成功保存,如图所示。
查看 MongoDB,下载成功的图片信息同样已成功保存,如图所示。
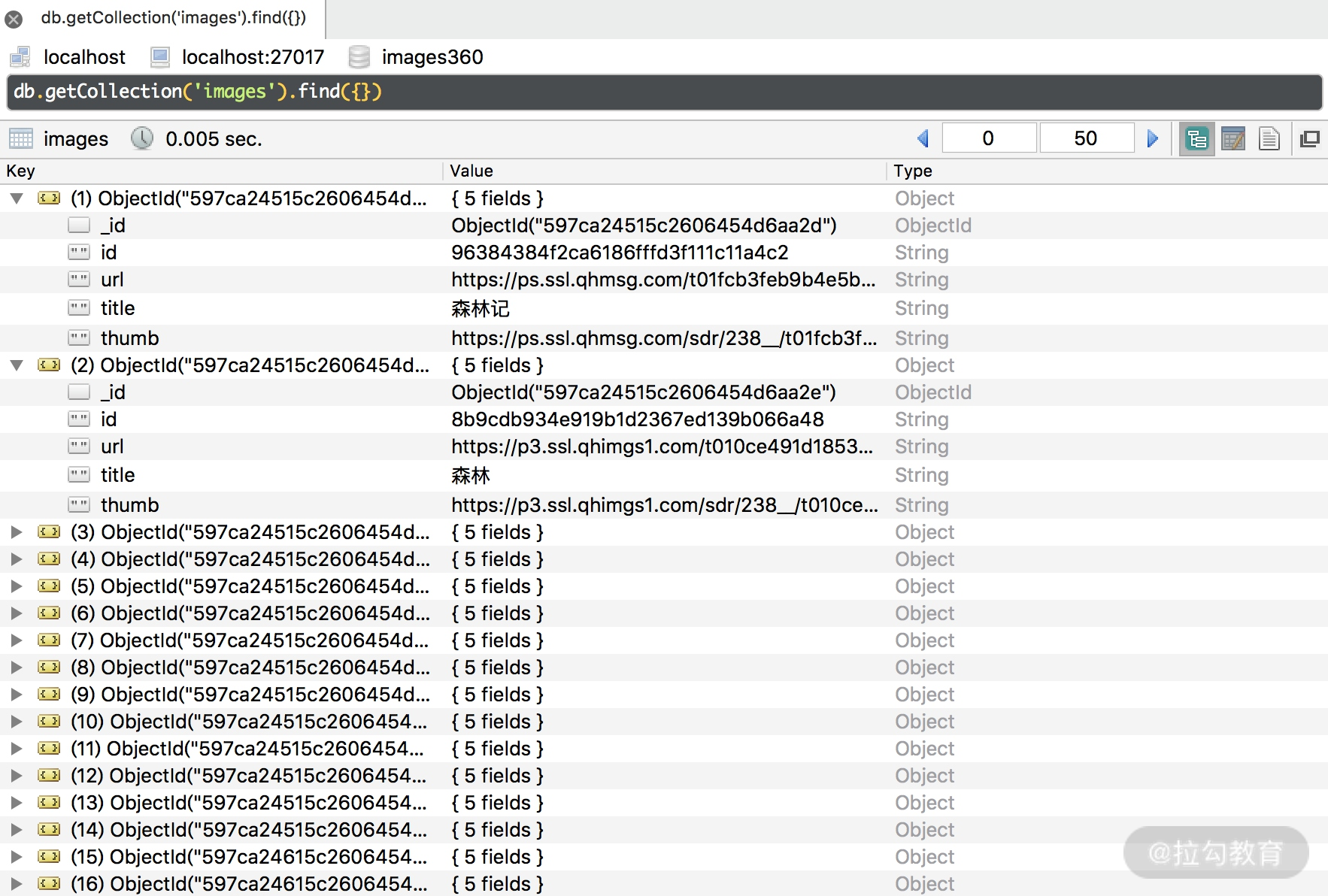
这样我们就可以成功实现图片的下载并把图片的信息存入数据库了。
9. 本节代码
本节代码地址为:
https://github.com/Python3WebSpider/Images360。
10. 结语
Item Pipeline 是 Scrapy 非常重要的组件,数据存储几乎都是通过此组件实现的。请你务必认真掌握此内容。